
データの信頼度を推定する統計的手法【前編】
はじめに
機械学習においてデータの重要性を強調しすぎることはありません. 信頼性の低い, あるいは偏りのあるデータを使用してしまった場合には機械学習の結果は無意味なものになってしまいます. 近年著しい発展を遂げている深層学習は大規模なデータを必要とするため, データセット構築のためにクラウドソーシングが用いられる事が多くなってきました. 機械学習のためのデータ収集においては, 主にマイクロタスク型のクラウドソーシングが用されます. クラウドソーシングを用いることにより大規模なデータ構築が可能となりますが, 多数の不特定な作業者にタスクを依頼するため成果物の品質管理が課題となります. このような背景において, 機械学習のためのデータの信頼度を推定する方法の重要性はますます高まっています. 本記事では,人間による評定結果に基づいて統計的にデータの信頼度を推定する手法について説明します 1.
この記事の前編では, まず始めにデータ構築のワークフローを整理します. 次にデータの信頼性に影響する要因について紹介します. 最後にデータの信頼性を推定するための統計的手法の中でも基本となるDawid-Skeneアルゴリズムを例にとって, その概要を説明します. 後編ではDawid-Skeneアルゴリズムを詳しく定式化したあと, さまざまな拡張・その他の手法について紹介します. さらに言語資源と評価に関する国際会議 LREC 2020 に採択された我々の 論文 についても紹介します. 最後にデータ信頼度を推定するための統計的手法の利用方法について整理して, 本記事をまとめます.
前編の概要
- データセット構築のワークフローを「作成ステップ」「評価ステップ」に分けて考えます.
- データの信頼性に影響する要因として「データ作成者の知識・能力」「データ評価者の知識・能力」および「タスクの明確性・客観性」などがあります.
- 従来手法として評価者による多数決があります. しかし多数決では信頼性の高いデータを正しく選択できない場合があります.
- データの信頼度を適切に推定するためには, 想定するタスクの性質に応じた統計的手法を使う必要があります.
データ構築のワークフロー
まず始めにデータ構築のデータフローについて整理します. 典型的なデータ構築のワークフローは以下の2つのステージにより構成されます.
- データ作成ステップ
- データ評価ステップ
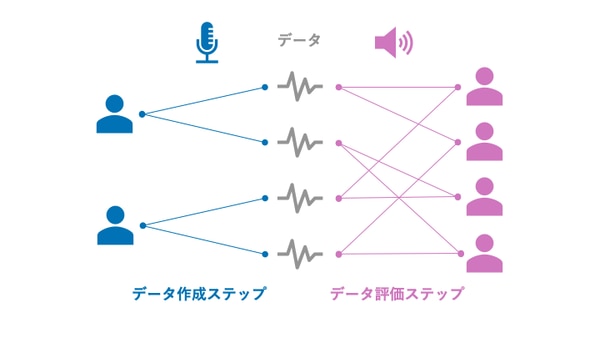
データ作成ステップでは, 所定の条件に従って作業者に何らかのタスクを実行してもらい, テキスト・画像・音声・動画などのデータを作成します. このような作業をデータ作成タスクと呼ぶことにします. 例えば条件に合致した文を作成する, 所定の文を読み上げて録音する, 指定された物の写真を撮影するなどの作業が考えられます. あるいはWikipedia, Freesound, Flickr, YouTube, Wikimedia Commonsなどのインターネット上のリソース 2 からデータを収集して来ても構いません.
データ評価ステップでは, 作成・収集されたデータを別の作業者に評価してもらいます. このような作業をデータ評価タスクと呼ぶこととします. 例えばテキストを単語分割する, メールのスパム判定, 写真の被写体を所定のクラスに分類する, アイコン画像の好き嫌いを評価する, 音声を書き起こす, 音声の感情を所定のクラスに分類するなどの作業が考えられます. 作業ミス・評価者の作業ルールに関する誤解・判断基準の偏りなどの影響をを避けるために, 1つのデータを複数人が評価者にタスクを割り当てます. また, 各評価者が複数のデータを評価するようにタスクを割り当てます.
データ作成ステージとデータ評価ステージから構成されるワークフローの結果, データとその評価結果のセットが得られます. データ作成作業とデータ評価作業の内容は想定している機械学習のタスクに応じて設計されます.
クラウドソーシングにおける予選ラウンド
クラウドソーシングの各ステージにといて予選ラウンドを設けることも可能です. このラウンドではクラウドワーカーには少数のタスクが提示されます. それらの成果物を分析した結果, 十分な知識・スキルを有していると判定された作業者がメインラウンドに進みます. メインラウンドでは多数のタスクがクラウドワーカーに提示されます.
予選ラウンドにおいて作業者の信頼性の判定する方法として, 正解付きのデータ(ゴールドスタンダート)を用いる方法や, 専門家による判定などがあります.
データの信頼性に影響する要因
上記のワークフローに沿って得られたデータすべてについて, 必ずしも高い信頼性があるとは限りません. どのようにして評価結果に基づいてデータの信頼度を推定すればよいのでしょうか? 信頼度を推定する手法について紹介する前に, どのような要因が信頼性に影響を及ぼすかについて考えます.
必要なデータが小規模であれば, データ作成・評価を専門家に依頼する事により信頼性を担保できるかもしれません. しかし大規模なデータセットを構築する場合には, このような方法は現実的ではありません. そこでクラウドソーシングの枠組みを利用することを考えます. このような場合, クラウドワーカーのタスクに関する知識や能力にはばらつきがある事に注意が必要です. したがって十分な知識・能力を持った作業者を見つけ出すことが重要となります. 例えば動物の写真を犬・猫・その他に分類するタスクであれば, 特別な知識やスキルは要求されないでしょう 3. 音声を聞いて雑音が混じっていないか判定するタスクの場合には, 作業者間で大きな不一致はないものの, 人によって雑音と判断する基準にばらつきがあることが予想されます. 画像からキノコを同定するタスクであれば, 専門知識がある作業者を見つけ出す必要があるでしょう. 上記のことから「作業者の知識・能力」および「タスクの難易度」がデータの信頼性に影響することが分かります.
またデータ作成タスク・データ評価タスクが, 作業者の考え方の傾向・価値観など主観的要素に影響される場合もあります. このようなタスクに対しては, "唯一の正解" を客観的に定めることが出来ません. 結果として, 作業結果のばらつきは大きくなり, 高い知識・スキルを持っている人を特定することは困難になります. また 許容される "正解" に複数のパターンがあるようなタスクにおいては, 作業者がいくつかのクラスターに分かれる場合があります. 例えばロゴ画像の作成・評価タスクを考えると "よいロゴ" の基準は主観によって左右されます. このような場合でも多数の人が高く評価するようなロゴや, そのようなロゴを作成するデザイナーを見つけ出すことはできるかもしれません. 感情を込めた音声の録音・評価タスクの場合には, 感情の表出方法は発話者ごとに千差万別であり, 同じ音声を聞いたときに感じる感情は評価者ごとに傾向がことなる可能性があります.
このように「タスクの明確性・客観性」および「作業者の考え方の傾向」がデータの信頼性に影響を及ぼします. したがってデータの信頼度を推定するためには, タスクの性質に応じた適切な手法を選択する必要があります.
データの信頼度を推定する方法
以下では, データの信頼度を推定する手法について紹介していきます.
まずはデータ作成ステップは考慮から外して, データ評価ステップに焦点を当てます. 評価タスクの方式はいくつかの典型的なパターンがあります. 例えばクラス分類・数値評価などが一般的によく使われます. この他にも2つのデータを比較して片方を選択する方式も考えられます. 評価作業の結果に基づいてデータの信頼度を推定することは, このような評価結果を定量的に集約する作業であると言えます.
票数カウント
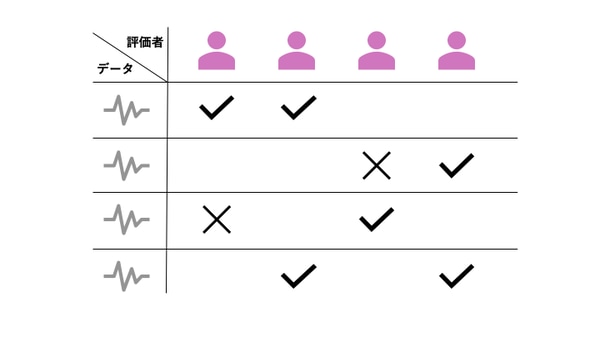
クラス分類による評価の場合によく用いられるのは方法は, 評価者による多数決です. この方法では各データに対してもっとも多くの票を獲得したクラスを採用します. 1つのデータに対して複数のクラスを対応付けることが許されている場合には, 過半数の評価者が付与したクラスをすべて採用します.
評価者の投票数をカウントする方法では,データの信頼度は得票率により定量化されます. 例えば, ある画像に写っているのが犬であるか否かという二値分類による評価タスクを考えます. 犬であると判定した評価者の割合は, 犬の画像としての信頼度の指標として解釈することができます. より高い信頼度のデータのみを抽出したい・より多くのデータが欲しい場合には, しきい値を過半数から上げる・下げることも可能です.
票数カウントは データ評価タスクの正解が1つに定まり, 特別な知識・能力を必要としない(したがって多数決の結果が信頼できる)場合に有効です.
スコア平均
評価タスクが数値評価である場合には, 評価スコアの平均がよく用いられます. 例えば音声の聞き取りやすさを5段階で評価するタスクを考えます. 評価者が付けたスコアの平均値は, その音声を聞き取りやを数量化していた値であると言えます. この値は聞き取りやすい音声としてのデータの信頼度としても解釈することができます 4. スコア平均は客観的な数値評価が可能であり, 特別な知識・能力を必要としない場合に有効です 5.
統計的手法
票数カウントやスコア平均により評価結果を定量的に集約する方法では, すべての評価者が平等に扱われていました. すなわち, すべての評価者が同程度に信頼できる(同程度の確率で誤った評価を行う)ことが仮定されています.
しかし実際には作業者の評価スキルにはばらつきがあります. 評価スキルのばらつきが大きい場合には, 票数カウントを用いるためには評価者の人数を増やす必要があります. さらに, 正しい評価を行うために専門知識や特別なスキルが必要とされる場合には, 評価者の人数を増やしたとしても, 多数決の結果が正しいとは限りません. このような場合には適切な知識・スキルを有している・適切にタスクを遂行できる作業者のみを見つけ出す必要があります.
すなわちデータの信頼度を推定するためには, 評価者の能力を知る必要があります. 一方で評価者の能力を推定するためには, データの信頼度を知る必要があります 6. しかしながらどちらも未知の量であるため, このままではどちらの値も推定することができません. そこでデータの信頼度を潜在変数とみなした上で, 作業者による評価結果に基づいてそれらの値を統計的に推定することを考えます. 以下では, このような統計的なデータ信頼度の推定方法について紹介していきます.
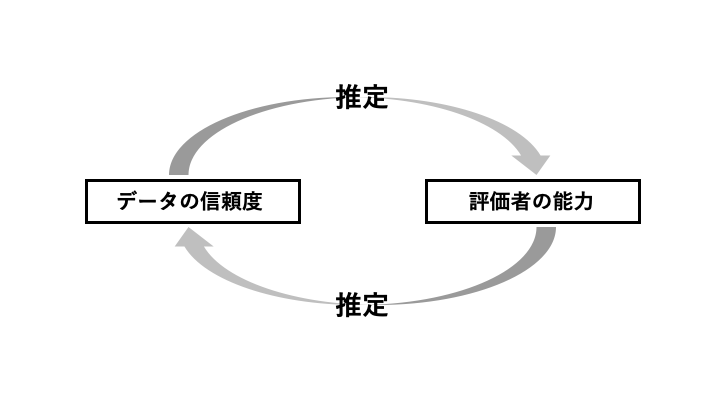
Dawid-Skeneアルゴリズム
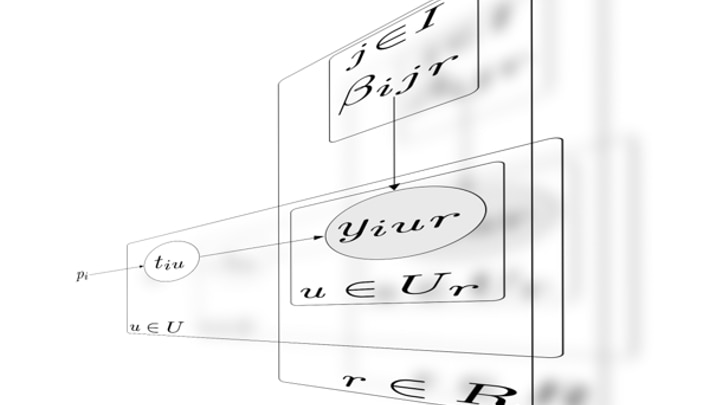
データ評価者の能力とデータの信頼度を同時に推定する統計的手法として基本となるDawid-Skeneアルゴリズム [2] の概要を説明します.
ここでは簡単のためデータ評価タスクとして2値分類を考えます. 例えば写真画像に鳥が写っているか否か, 音声が読み上げている文章が日本語か英語か, 文章の極性がポジティブ・ネガティブどちらであるかなどの評価タスクが該当します. Dawid-Skeneアルゴリズムではデータの真のラベルを潜在変数, 評価者の正解率をパラメータとみなします. ラベルを表す潜在変数として一方のクラスには0, もう一方のクラスには1を対応させます. これらのクラスをクラス0, クラス1と呼ぶこととします. なおDawid-Skeneアルゴリズムでは, データ作成者については考えません.
データのラベルの期待値と, 評価者の正解率はEMアルゴリズムにより同時に推定されます. すなわち, 評価者の正解率を既知のものとしてデータのラベルを推定する, データのラベルを既知のものとして評価者の正解率を推定するステップを交互に繰り返します. 各データのラベルの期待値は0.0から1.0の値を取ります. ラベルの期待値が0.0に近いデータはクラス0に属するデータとして信頼性が高いと言えます. 同様にラベルの期待値が1.0に近いデータはクラス1に属するデータとして信頼性が高いと言えます. 一方でラベルの期待値が0.5に近いデータはいずれのクラスとしても信頼性が低いと判断できます. このように各データについてラベルの期待値は, データの信頼度を表していると解釈できます.
拡張とその他の手法
Dawid-Skeneアルゴリズムは多数派と同じ回答をしている評価者を信頼できるという 仮定の下で, データと評価者と信頼度を同時に推定していると言えます. このような条件はどのようなタスク成立するとは限りません. タスクの性質に応じて, さまざまな拡張・異なる手法が提案されています. 例えば以下のような場合への拡張が挙げられます.
- (5段階評価など) 数値評価による評価タスク
- 与えられたデータペアを比較する評価タスク
- 評価タスクの難易度にばらつきがある場合
- 評価者と評価タスクに相性がある(評価者ごとに得意不得意がある)場合
- 評価者の判断基準の偏りがある場合
- 少数の専門家が正しい判定を行えるが, 一般の作業者には正解が分からない場合
- 評価者の回答パターンが複数のクラスターに分かれる場合
- 主観に左右される評価タスク
- データ作成者の知識・能力も考慮する場合
想定するタスクの性質に応じて適切な統計的手法を選択する必要があります. 既存の手法の中で適切なものがあるとは限りません. もし適切な手法が見つからなかった場合には, 想定するタスクの性質に基づいて既存の手法を拡張する必要があります. 目の前の課題に合わせた手法を自分の手で定式化する上でも, 既存の手法の性質を理解しておくことは大きな助けとなるでしょう.
前編のまとめ
本記事の前編では, クラウドソーシングによるデータ収集における典型的なワークフローを整理した上で, データの信頼度に影響する要因について説明しました. さらにデータ評価ステップに着目して, 評価者の信頼度とデータの信頼度を推定する統計的手法の基礎となるDawid-Skeneアルゴリズムの概要とその前提条件について紹介しました.
後編ではDawid-Skeneアルゴリズムをより詳しく定式化した上で, さまざまな拡張やその他の手法について紹介します.
参考文献
- [1] 鹿島 久嗣, 小山 聡, 馬場 雪乃, "ヒューマンコンピュテーションとクラウドソーシング," 講談社, 2016.
- [2] A. P. Dawid and A. M. Skene, "Maximum Likelihood Estimation of Observer Error-Rates Using the EM Algorithm," Journal of the Royal Statistical Society, Series C (Applied Statistics), Vol. 28, No. 1 (1979), pp. 20-28.






